以下罗列了部分 BQ 中进行随机抽样的方法:
1. RAND() 函数
RANK 函数生成 0,1 范围内的 FLOAT64 类型的随机值,使用 RANK() 生成随机值,然后使用 ORDER 进行排序,并取前 n 行,即可完成完全随机抽样。
#standardSQL
SELECT
RAND() a以下罗列了部分 BQ 中进行随机抽样的方法:
RANK 函数生成 0,1 范围内的 FLOAT64 类型的随机值,使用 RANK() 生成随机值,然后使用 ORDER 进行排序,并取前 n 行,即可完成完全随机抽样。
#standardSQL
SELECT
RAND() aBQ ML 这款直白来说,就是让你在 BQ(BigQuery) 中,通过 SQL 语句来完成一些简单的机器学习任务。
其最大的特点就在于: 1)使用 SQL 2)内置了部分经典算法(甚至可以使用 Tensorflow) 3)BQ 速度很快 4)其他
你说这个有没有用呢,其实也有点,你要说多有用,其实
实话实说,vultr 真是太方便了,你可以建一个机场,搭好之后存一个快照,然后用,不用了,删除实例,不花钱了。 但是下次你需要用的时候,只需要在创建实例的时候,选择用快照创建,就可以快速复原之前的机场,密码、IP都不变,贼方便。
方便又便宜!
在使用 PySpark 的时候,经常会遇到如下场景:
Spark 采用了 DAG 的计算流,直到一个实际的 Action 时才会真的发生运算,这在实际生产
from pyspark.sql.functions import array
test = df.select(array('col1', 'col2').alias('array_cols'))
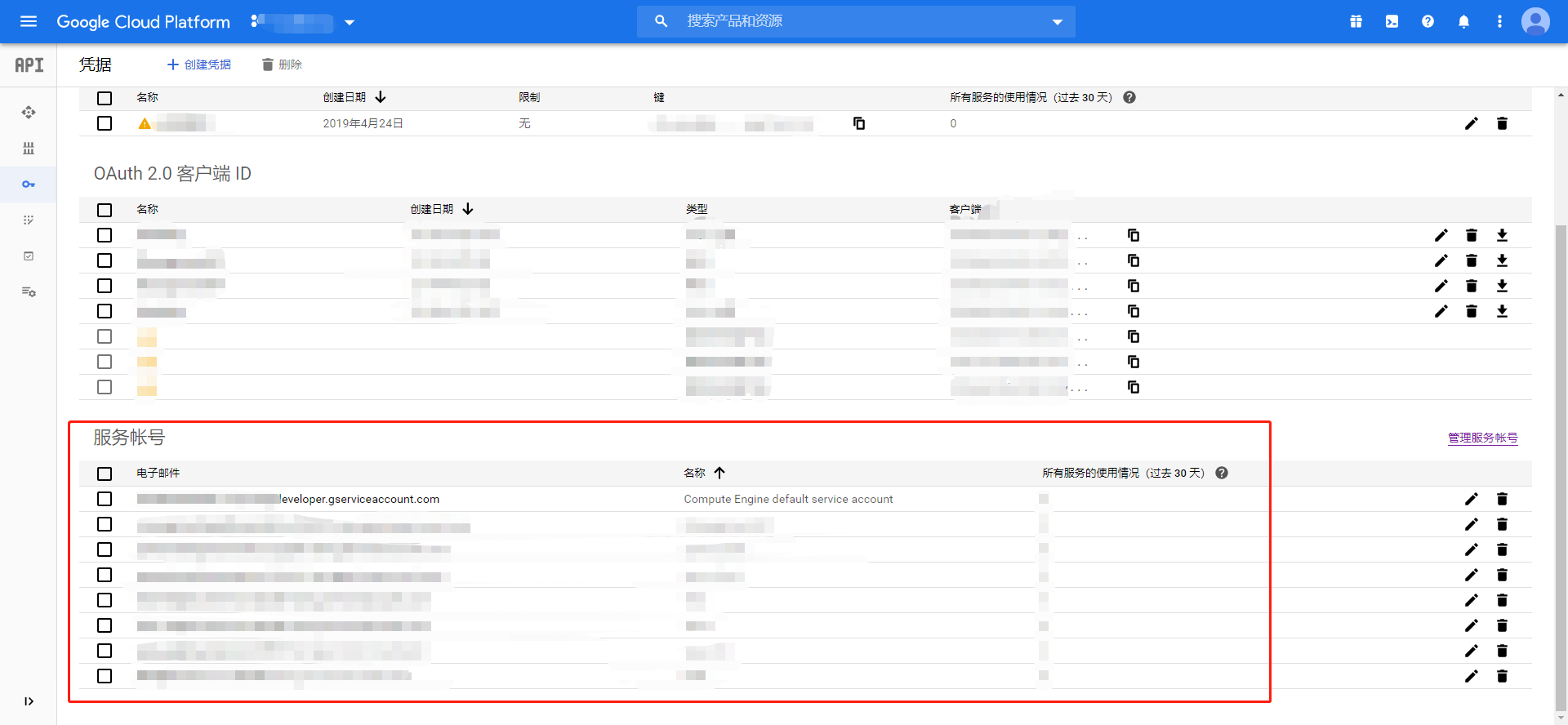
最近发现 GCP 凭据 服务账号 JSON 密钥的下载方式,有所更新,此处记录一下。
现在下载服务账号 JSON 密钥的方式如下:
点击服务账号,进入服务账号详情页
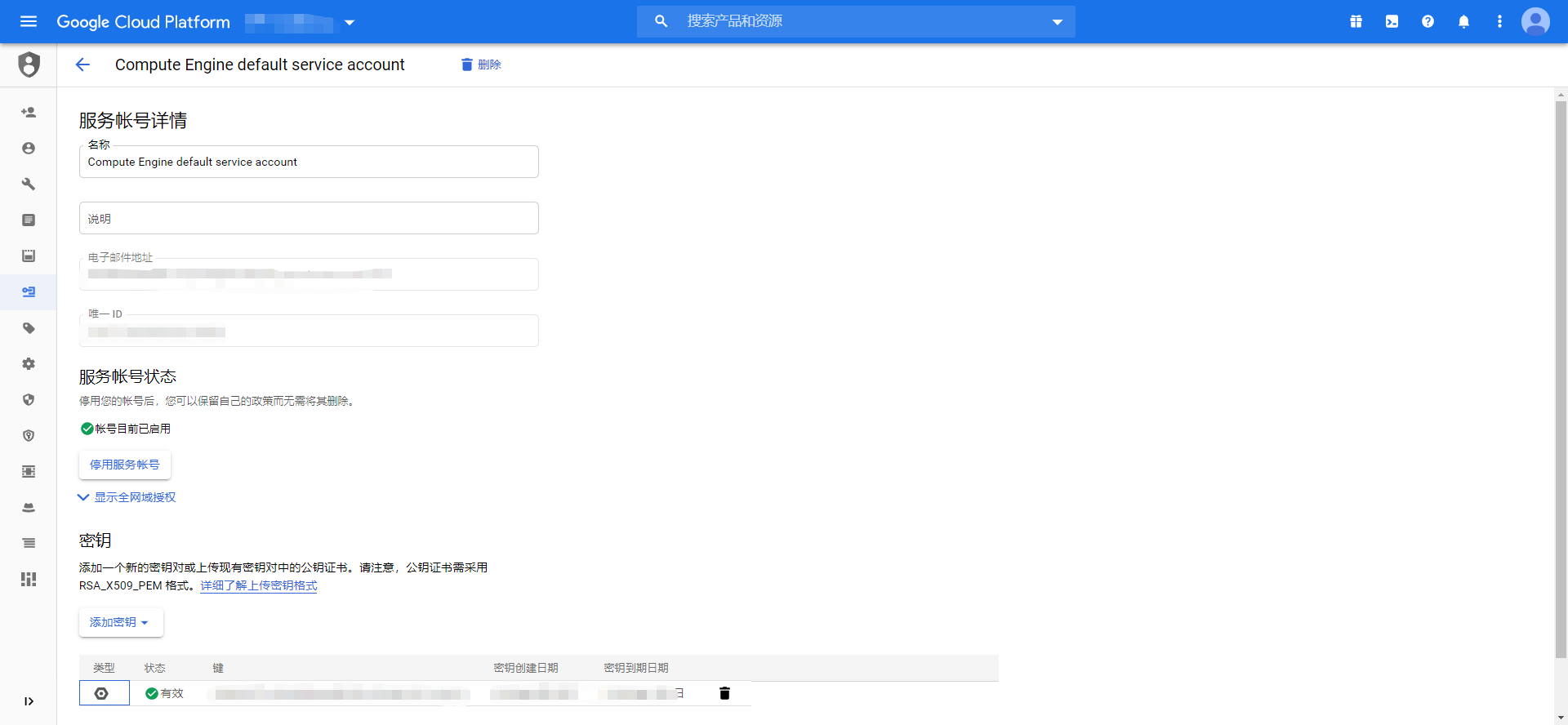
在服务账号详情页中,点击 密钥 - 添加密钥
创建新的密钥,此时会自动下载 JSON 格式密钥文件
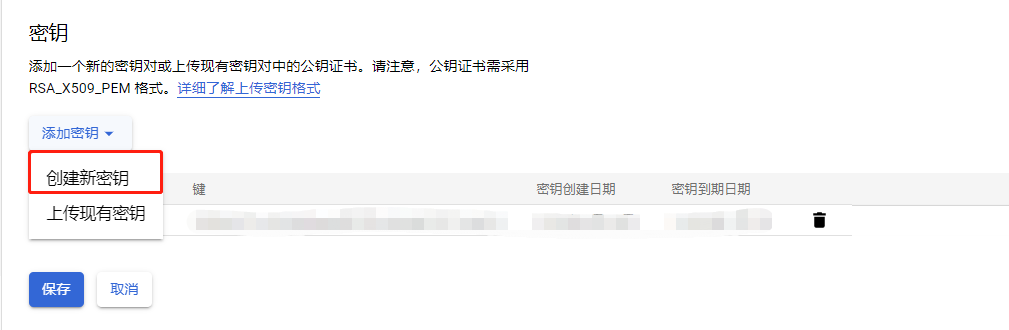
完成保存即可。
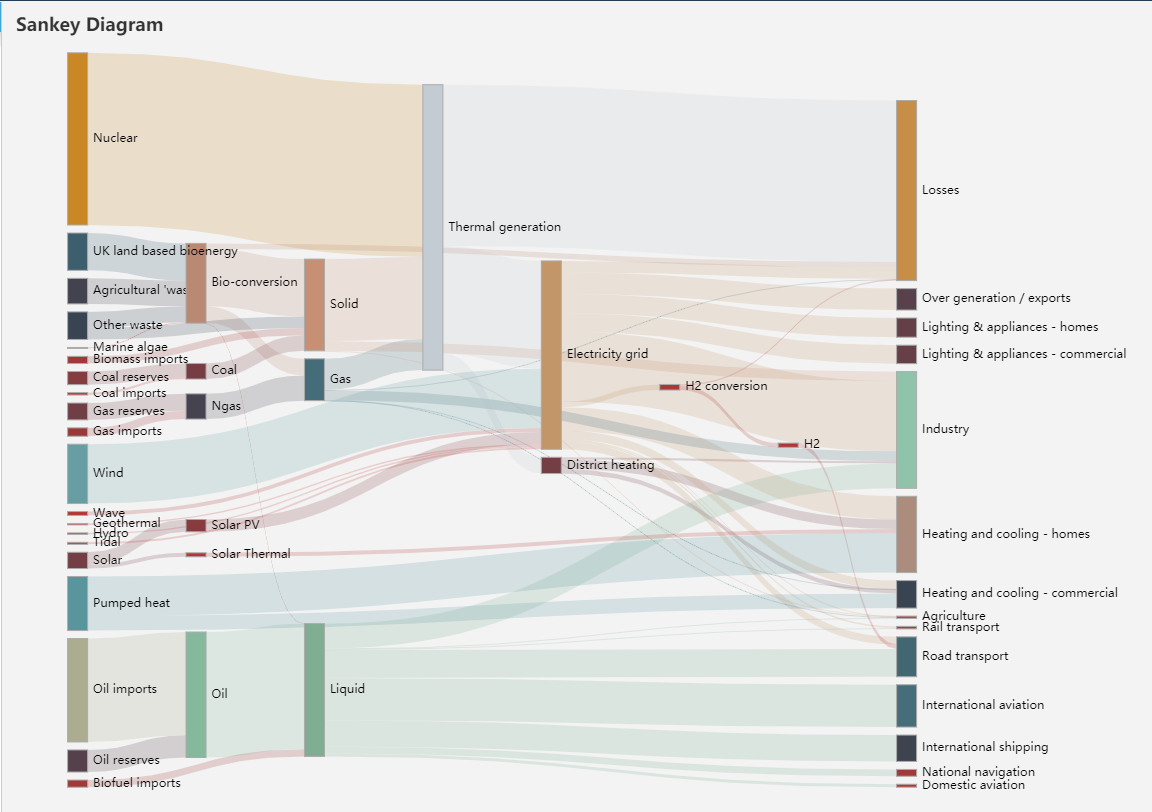
拿一个官网的效果图做示意:
以下为 SQL 语句:
WITH `all_data` AS ( -- 原始数据集
SELECT `source`,
`target`,
`level`,
`value`,
`BigQuery 的窗口函数,官方称呼为 “分析函数”(官方文档链接)
语法上和常规 SQL 语法基本没有太大差异,如下所示:
analytic_function_name ( [ argument_list ] )
OVER { window_name | ( [ window_specifi最近遇到了一个 bug,即
f'xxxx{a}'这种语法,在 python3.5 版本上运行不了,查了一下,发现这个特性是 3.6 后出现的,为了适配,还是换回了原来 .format() 的形式。
关于版本的更新内容,可以参考如下链接: