对于 ManyToMany 元素,Django Admin 默认使用的筛选组件为:
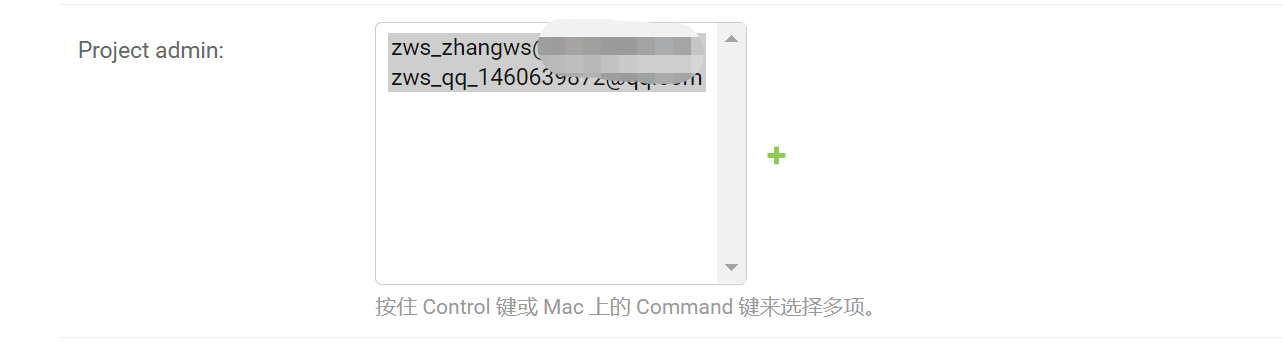
如上图所示,使用的时候很是麻烦,而且不太直观。
而另一种 Django 提供的方式,则使用体验好的多,如下所示:
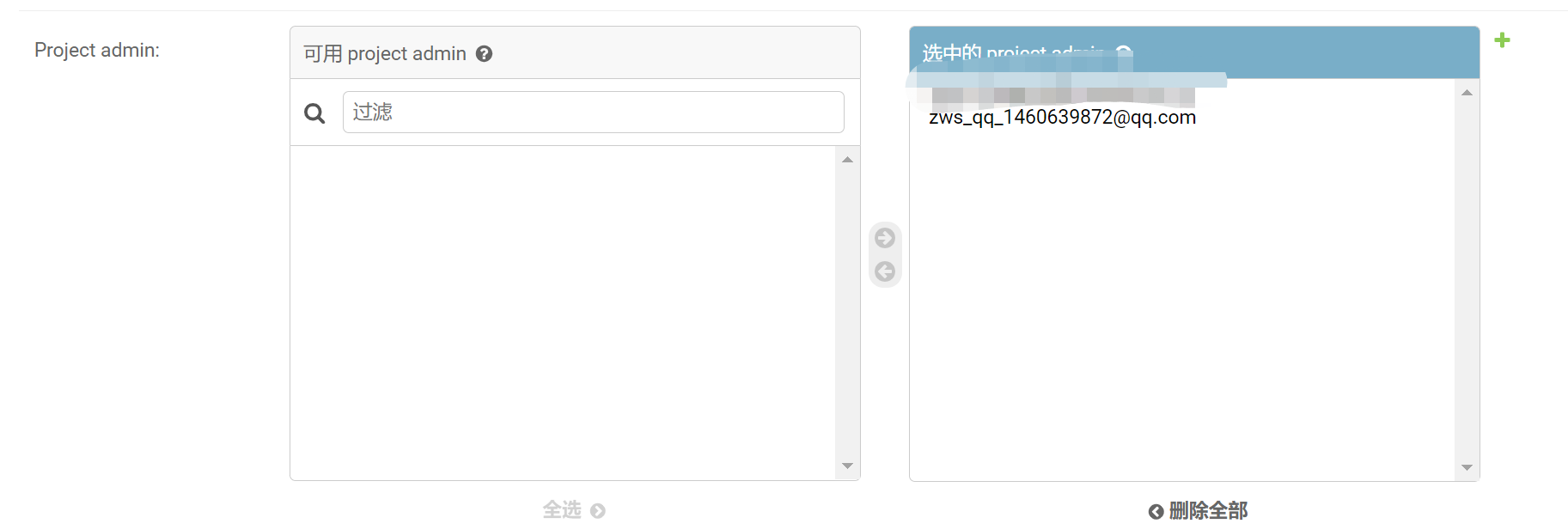
想要设置采用如下方式,在对应 APP 下做如下设置即可:
class ModelName(admi分类目录归档:Python
对于 ManyToMany 元素,Django Admin 默认使用的筛选组件为:
如上图所示,使用的时候很是麻烦,而且不太直观。
而另一种 Django 提供的方式,则使用体验好的多,如下所示:
想要设置采用如下方式,在对应 APP 下做如下设置即可:
class ModelName(admi在 python 中,我们通常使用 virtualenv 来进行虚拟环境的安装,但是在 Linux 上,由于默认的 python 是 python2
直接使用 virtualenv 命令,构建的虚拟环境,同样会基于 python2。
如果想要基于 Python3 可使用如下命令:
virtualen在我们开发 Python 项目时,经常会遇到项目目录下,子目录间模块导入的问题,例如:
我拥有如下目录 python-test:
├─bin
│ start.py
│ __init__.py
│
└─utils
│ base.py
│ __init__.py最近遇到了一个 bug,即
f'xxxx{a}'这种语法,在 python3.5 版本上运行不了,查了一下,发现这个特性是 3.6 后出现的,为了适配,还是换回了原来 .format() 的形式。
关于版本的更新内容,可以参考如下链接:
有的时候,我们需要根据给定的映射关系,对数据进行替换,比如 餐厅老板 替换为 1
我们可以使用 Pandas 的 map 方法,来快速实现这一需求。
data={
'USER_ID': ['张三', '李四', 我们经常会遇到这种需求: —— 将数据按照某个维度的值进行分组(例如:USER_ID),然后针对某个值进行组内排序(例如:SCORE),并标注序号
比如: 在推荐系统的召回阶段,我们会为每个用户推荐数个产品,并赋予其不同的得分,有时我们就需要对同一用户,不同推荐产品的得分进行排序,并标注序
当使用 pandas 的 groupby 功能时,如果不设置 as_index 为 False, 那么 groupby 默认会把做 groupby 的 col 作为 index 来使用。 如果存在多个 col,则形成的是 multiIndex。
如果这个时候需要把此时作为 index 的数据提取出来
Haystack 为 Django 提供模块化搜索,它具有统一、标准的API,可以配合不同的后台,例如:Solr / Elasticsearch / Whoosh 等等,而无需修改代码。
pip install django-h